Chapter II: If a tiny transformers.js transcription model can understand your articulation - you’re good
Table of Contents
Self growth
The most outstanding fact I figured out when I started recording my voice only during the meetings - no matter how good your AI model or hardware - nothing will help if you’re mumbling or not articulating words well. Of course, in some social circles it’s important to use slang, a specific tone and pace in order to be recognized and get your share of appreciation, but most of human communication, especially work-relevant communication, is successful if your speech can be transformed by other ears and brains into something they can understand.
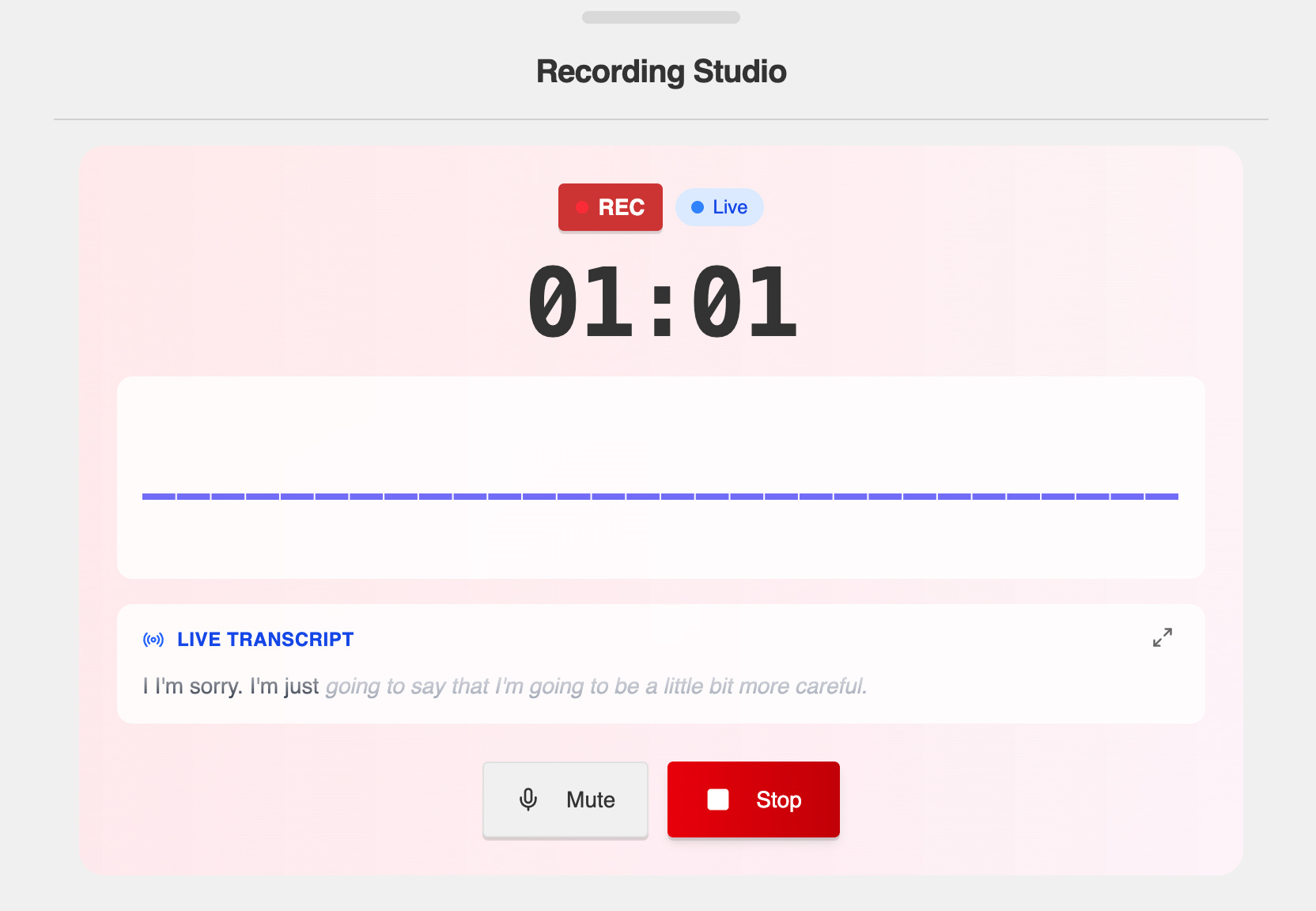
The same is for the AI models. Someone might expect it to recognize every detail and every single change of the tone of voice, but the reality is, even silence or white noise can generate some esoteric experience:
Transcription of the silence:
0:00 - I
0:15 - I’m sorry.
0:30 - I’m just going to say that I’m going to be a little bit more careful.
1:00 - I’m going to go to the bathroom.
But if you speak clearly, without rushing, and at an adequate volume, you can spin off voice transcription on your phone 24/7, even the live version of this. So I set this as a goal for myself and saw a drastic improvement in my meetings and voice memo transcriptions, as well as in the overall feedback from folks around me. Even if you’re away from your laptop, this behavioral piece stays with you.
Ecosystem
The brightest moment, from my POV, is the Whisper model from OpenAI. Since it made a lot of noise, we saw an increase in OSS models and fine-tuned versions, and even some attempts to revise it.
17,302 base Automatic Speech Recognition models you can find in Hugging Face.
Here is how the landscape has evolved over the last 4 years:
- September 2022 - OpenAI Whisper Open-Source Release OpenAI released an end-to-end transformer trained on 680,000 hours of multilingual audio. It proved that massive scaling of “weakly supervised” web data produced models that were vastly more robust than those from strictly curated, clean audio datasets.
- Late 2022 - whisper.cpp & Local Compute Release of pure C/C++ implementation of Whisper without PyTorch dependencies. Using the ARM NEON and Apple Metal frameworks enabled M-series hardware to run high-accuracy ASR locally without dedicated Nvidia GPUs, sparking the local-first AI movement.
- Mid 2023 - Transformers.js & ONNX Runtime Web Hugging Face’s Xenova brought the Python pipeline API to JavaScript. By compiling Whisper into the ONNX format and executing it via ONNX Runtime Web, browsers could run speech-to-text entirely client-side via WebAssembly (WASM), ensuring zero-latency network overhead and total user data privacy.
- October 2024 - WebGPU Acceleration & Whisper Turbo Transformers.js v3 launched with native WebGPU support. This bypasses WASM bottlenecks and unlocks significant speedups for in-browser ONNX inference. Simultaneously, OpenAI released Whisper Large V3 Turbo, a pruned model. This decoder was reduced from 32 layers to 4, achieving 216 times faster real-time processing speed with minimal accuracy loss.
- Mid 2025 - Speech-Augmented Language Models (SALMs) The open-source architecture shifted. NVIDIA released Canary-Qwen 2.5B, pairing a FastConformer speech encoder directly with an unmodified Qwen LLM decoder. It topped open leaderboards with a 5.6% average Word Error Rate (WER), marking a transition from dedicated ASR models to native multimodal language models.
- Early 2026 - The Commercial Real-Time War The enterprise market pivoted entirely to streaming latency for AI voice agents. OpenAI launched GPT-Realtime-Whisper as a dedicated low-latency endpoint. Deepgram introduced Flux, integrating end-of-turn detection directly into the model, while AssemblyAI rolled out Universal-3 Pro, a “speech language model” supporting natural language prompting.
Current state of compact Live transcription LLMs
17,302 base Automatic Speech Recognition models you can find in Hugging Face.
It’s not as broad as you can imagine if we touch OSS. About ~7k are free to use, but compact ones you can put into the browser tab are way less - 54 models. 54 models if you have a solid GPU and RAM capacity.
An incredible ability of improperly configured LLMs - when using Spanish during the conversation, because of EN flag by default, it still responds in English, so I had free, and quite fast, translations as well.
To see what we're going to deal with, I made a few runs:
- Textbook-clear dictation
- Synthetic speech-to-text generated data
- And my fav one is coffee shop conversations
When you feed them clear dictation, it works. As you may expect. No surprises at all, we’re living with this for the last 4 years.
Coffee shop - it starts hallucinating or dropping entire phrases. But this is not a problem because you can apply noise cancellation (at least a few strategies are available at the moment) and generate a decent transcription.
But audio generated by other TTS models exposed a different kind of architectural friction. Because AI-generated speech often lacks the organic micro-imperfections, natural cadences, and random imperfections of human vocal cords, the compact models occasionally over-correct obvious phrases.
The YouTube Speed Stress Test
To push the temporal limits of local client-side inference, I ran a final, meaningless experiment: transcribing YouTube videos at 1.5x and 2x playback speeds.
- At 1.5x speed: Doesn’t make any difference. The Word Error Rate (WER) is alright.
- At double speed: Picture using voice dictation in an early 80s car to update your navigation destination. That same quality.
Languages
I need to note that I tested it only in English, using English sources. You can spot that some of the OSS models are language-prefixed, such as EN, ES, or CN. To keep the model's size and quality balanced, you need to train it on a single language. Multilang models are slightly degraded in terms of performance but are still valid to use.
Ultimately, running live transcription in a browser tab is a remarkable engineering trade-off. If you can control your environment, articulate clearly, and keep the pace natural, a tiny local model will easily match a multi-billion-dollar cloud infrastructure. But the moment you introduce messy, double-speed real-world chaos, you realize exactly why those cloud models need giant data centers behind them.
For now.
References
- Schiller, I. S., Aspöck, L., & Schlittmeier, S. J. (2023). The impact of a speaker's voice quality on auditory perception and cognition: a behavioral and subjective approach. Frontiers in Psychology, 14. Link
- Smiljanic, R., & Bradlow, A. R. (2009). Speaking and Hearing Clearly: Talker and Listener Factors in Speaking Style Changes. Language and Linguistics Compass, 3(1). Link